
The students attending my masters-level class on Digital Approaches to Cultural Heritage in Spring 2024 were drawn from the London Intercollegiate Classics programme (students in Classics, Ancient History, Classical Art and Archaeology, Late Antique and Byzantine Studies, and Reception of the Classical World from King’s College London, Royal Holloway University of London and University College London) plus a few Institute of Classical Studies doctoral students auditing the module. The course was taught with the support of the Sunoikisis Digital Classics online programme, with common sessions on Youtube, and ten in-person seminars and practical sessions hosted in the Senate House MakerSpace.
To complement the readings provided through SunoikisisDC, we invited each student to contribute one suggested “reading” per week, ideally open access but not necessarily formally published articles (blog posts, videos, news reports, etc. were welcome) on the subject of the course: the intersection of digital humanities and the study of antiquity and heritage. I borrowed the idea for this collaborative reading list from my colleague Emlyn Dodd, and was delighted with the gusto and sensitivity with which the students took to it. The results of this year’s collaboration are reproduced below, including brief comments from the student who contributed each item (with the explicit permission of all students), with thanks and kudos to all.
The brief:
Please add below here at least one example per week of a reference you have found that is relevant to this course and might be of interest to the others. This need not be a formal publication, but can also include blog posts, videos or podcasts, wiki pages, websites, online editions or tools, etc. Explain briefly in the message why you found it useful, and be prepared to share it with the class in the Tuesday seminar.
|
Elliott, Tom. ‘Epigraphy and Digital Resources’. In The Oxford Handbook of Roman Epigraphy, edited by Christer Bruun and Jonathan Edmondson, 78–86. Oxford: Oxford University Press, 2014. https://doi.org/10.1093/oxfordhb/9780195336467.013.005. It is a fairly short chapter of the The Oxford Handbook of Roman Epigraphy. Tom Elliot introduces the reader to several digital epigraphic databases and editions, journals and references that are useful for further reading, as well as initiatives by associations like EAGLE in epigraphy. It is an excellent introduction to digital epigraphy for students or other scholars keen to learn more about digital humanities in general. |
|
Novotny, J. and K. Radner, ‘Official Inscriptions of the Middle East in Antiquity: Online Text Corpora and Map Interface’. in Crossing Experiences in Digital Epigraphy, eds. A. De Santis and I. Rossi, 141-153. Berlin: De Gruyter, 2018. This is a pretty brief overview of what the OIMEA (Official Inscriptions of the Middle East) project is and what it can offer scholars and those with an interest in the cultures of (primarily) ancient Mesopotamia. Most of the inscriptions they have included so far are in Akkadian and Sumerian, although they also intend to add Old Persian and Aramaic. I thought it would be useful to include here as it highlights some other benefits and difficulties found with digitised epigraphic databases (such as the difficulty of handling multilingual translations) that were not highlighted by the set reading. |
|
Codex Sinaiticus: https://codexsinaiticus.org/en/ Not an article, just a digital project, which I have come across in my course which I found interesting. The earliest surviving codex of the bible from the 4th century, this is in Greek. Website allows you to examine the original manuscript and to download some text in html I believe. |
|
https://ercolano.beniculturali.it/herculaneum3dscan/ Digital project called Herculaneum 3D Scan. It gives the occasion to scholars, cultural heritage specialists and the wider public to virtually visit several roman houses in Herculaneum. One of the nice aspect of this project is that you can download the 3D models and also calculate distance, volume and other things with webGL |
|
https://ijcs.ro/public/IJCS-17-04_Carlan.pdf Article from the International Journal of Conservation Science (Vol.8; Issue I-Jan-March 2017:35-42) describes how close-range photogrammetry was used to produce a 3D Model of ‘Arutel Roman Castrum’. Agisoft Photscan and Netfabb (for mesh editing) were applied to 2,200 photographs (all taken at ground level) and 270 m of walls were digitally modelled. The first author is from the Factulty of Geography in the University of Bucharest and the second author is a partner in a commercial company specializing in photogrammetry and GIS. |
|
https://sketchfab.com/rochestercathedral and/or https://www.rochestercathedral.org/virtual This is a link to photogrammetry scans of Rochester Cathedral, made by the Rochester Cathedral research guild (https://www.rochestercathedral.org/researchguild). I found this to be useful in my first year presentation on the cathedral, especially as it was during a covid lockdown and I could not visit the cathedral in person. In this way anyone including academics across the world can experience the cathedral’s architecture. |
|
Karagkounis, D, and S. Tsanaktsidou, ‘The Restoration of the Main Theatre of the First Ancient Theatre of Larissa, Greece, Assisted by 3D Technologies’. in Transdisciplinary Multispectral Modeling and Cooperation for the Preservation of Cultural Heritage, edited by A. Moropoulou; A. Georgopoulos, 13-23. Switzerland: Springer. Interesting chapter on how 3D modelling/mapping can be used in the reconstruction of ancient sites (specifically a Hellenistic theatre in Larissa). I included it since Thessaly is one of those regions that has not received much attention archaeologically so I was interested to see how 3D technologies had been used here. It also gives a different view from assigned readings about the utility of creating 3D models, i.e. to aid in restoration efforts. |
|
Leore Grosman, Avshalom Karasik, Ortal Harush, & Uzy Smilanksy. (2014). Archaeology in Three Dimensions: Computer-Based Methods in Archaeological Research. Journal of Eastern Mediterranean Archaeology & Heritage Studies, 2(1), 48–64. https://doi.org/10.5325/jeasmedarcherstu.2.1.0048 A good overview of the use of photogrammetry as part of the archaeological investigation, summarising the process of making digital 3D models before highlighting the numerous applications of such; including – and particularly usefully – how digital 3D models, through the development of new computer algorithms, can reveal historical answers from material remains that we would otherwise struggle or be unable to provide. |
|
Weiland, Jon. 2021. Review: Pleiades. https://classicalstudies.org/scs-blog/jon-weiland/review-pleiades Blog reviewing the digital gazetteer Pleiades, the leading geographical gazetteer in Digital Classics. The author presents a summary of the tool and its features, its growth, as well as strengths and weaknesses. It is a very good introduction on how Pleiades should be used and its importance in Digital Classics. |
|
Ryan Horne (2020) Beyond lists: digital gazetteers and digital history, The Historian, 82:1, 37-50, DOI: 10.1080/00182370.2020.1725992 This arrival discusses the advantages brought by digital Gazetters over physical ones, in that they have no limitations on the display and number of information they can provide, and how they can be connected by using a standard URI and through Recongito, added to other documents, as discussed in the lecture. |
|
Foka, A., McMeekin D. A., Konstantinidou, K., Mostofian, N., Barker, E., Demiroglu, O. C., Chiew, E., Kiesling B. and Talatas L. 2021. Mapping Ancient Heritage Narratives with Digital Tools. In: Champion, E. M. (ed.) Virtual Heritage: A Guide. Pp. 55–65. London: Ubiquity Press. DOI: https://doi.org/10.5334/bck.f. License: CC-BY-NC This book chapter examines the 2nd c. CE Periegesis Hellados (Description of Greece) by Pausanias. The narrative covers journeys between sites in Greece and exceptional objects found there. The chapter discusses the use of Recogito and the issue of ‘teasing apart’ movement, memory and space and how they interrelate. The authors used collection of gazetteers such as Pleiades, Topstext, Judith Binders Art History and that of the German Archaeological Institute (DAI). |
|
Grossner, K., Janowicz, K., & Keßler, C. (2016). Place, Period, and Setting for Linked Data Gazetteer. In M. L. Berman, R. Mostern, & H. Southall (Eds.), Placing Names: Enriching and Integrating Gazetteers (pp. 80–96). Indiana University Press. https://doi.org/10.2307/j.ctt2005zq7.11 The article explores how the methodological framework of Linked Data (i.e., the combination of multiple reference frameworks in a standardised ontological pattern) can enable the construction of comprehensive digital historical gazetteers which meet criteria of extensibility, multivocality, integration, and sustainability. It also further delineates additional requirements for comprehensiveness, such as the need for inclusion of temporal components alongside spatial components. |
|
Mafredas, Thomas & Malaperdas, George. (2021). Archaeological Databases and GIS: Working with Databases. European Journal of Information Technologies and Computer Science. 1. 1-6. 10.24018/compute.2021.1.3.20. DOI :10.24018/ejcompute.2021.1.3.20 This article focuses on how a database can provide a detailed record of archaeological excavations and a DB’s subsequent use in GIS research. The authors list the advantages of structuring data in a database environment, which attribute data should be selected and, how data entry becomes more efficient and more accurate when using handheld devices on site. It is also noted that updating and changing the database should be considered when compiling it. In the second part of the article an excavation project (Bethsaida, Israel) is briefly outlined. It describes how its database of the material finds (coins, Glas, metal, ceramics) was incorporated into the GIS research. The aim was to map geographical locations of different material objects in their respective historical time layers. |
|
Parlıtı, U. (2021) ‘An Evaluation on Eastern Anatolia Late Iron Age I added this article since I thought it would be interesting to see how GIS is used outside of articles with GIS as their primary focus. It uses GIS minimally, but still in an interesting and useful way. The article is a survey and reassessment of available archaeological data in Achaemenid Armenia. They use GIS to make a map that pinpoints each important location that is discussed in the article. This is a very useful application of this approuch since the article serves as an introduction to the available evidence in this field. People, such as myself, who dont know a lot about this Achaemenid satrapy are therefore not left in the dark about where everything is that the author is talking about. This is especially helpful for people studying the Achaemenid Empire since you do need to bounce around different regions to understand how the wider imperial administration works even if you focus on one area, so making the article very accessible to non-specialists on ancient Armenia is very helpful! |
|
Archaeology Data Service, n.d. ‘Guides to Good Practice.’ https://archaeologydataservice.ac.uk/help-guidance/guides-to-good-practice/ The Guides to Good Practice, created jointly by the UK Archaeology Data Service (ADS) and Digital Antiquity in the US, are a series of digital archaeology guides seeking to provide a basis for archaeological workflows that will produce shareable, archivable digital data. They include a comprehensive and detailed array of information packets on topics such as basic components of digital archaeology, types of data collection and fieldwork, and methods of data analysis and visualisation; the lattermost of which includes the applications and current issues of GIS use, how to create, use and archive GIS datasets, and more. |
|
Ruggeri, F, Crapper, M, Snyder, JR & Crow, J 2017, ‘A GIS-based assessment of the Byzantine water This article examines the 4th and 5th century aqueduct of Constantinople using GIS, which uses GPS data of the various aqueducts but also included a Digital elevation model using an ‘Advanced Spaceborne Thermal Emission and Reflection Radiometer’ |
|
Parcero-Oubina, C, Smart, C and Fonte, J. 2023. Remote Sensing and GIS Modelling of Roman Roads in South West Britain. Journal of Computer Applications in Archaeology, 6(1): 62–78. DOI: https://doi.org/10.5334/jcaa.109 This article presents a recent study on a more than likely road network system in the southwest of Roman Britain. This region is far less studied than other parts of England because of the scarcity of evidences. The authors used LiDAR from national surveys to build a GIS database and used this database for GIS spatial analysis of possible roads between settlements, possible roman sites and Roman forts. To overcome the downfalls of an exclusive least cost paths analysis, they also used MADO and CMTC. |
|
This article (2016) treats the 3D model of the Roman arch (dated to reign of Septimius Severus/193-211 CE) in Palmyra that was destroyed by ISIS in October 2015. The article notes that cultural appropriation of the town’s ruins occurred before the 21st century in the seal of the USA and the ceiling of the Freer-Sackler galleries. |
|
Timofan, Anca, Călin Șuteu, Radu Ota, George Bounegru, Ilie Lascu, Radu Ciobanu, Dan Anghel, Cătălin Pavel, and Daniela Burnete. “PANTHEON 3D. An Initiative in the Three-Dimensional Digitization of Romanian Cultural Heritage.” Studia Universitatis Babeș-Bolyai Digitalia 63, no. 2 (March 15, 2019): 65–83. https://doi.org/10.24193/subbdigitalia.2018.2.05. This paper talks about the cool stuff happening with Romanian history and tech. The National Museum of Unification in Alba Iulia is leading a big project called Pantheon 3D. They’re using fancy 3D scanning and modeling to make virtual versions of ancient Roman stuff. The goal is to create a digital collection and a cool website where you can explore it all. They want to use these digital goodies in museums, schools, and research to make learning about history more awesome. By teaming up with other groups, they’re hoping to find new ways to save and appreciate our shared heritage. This paper says that using 3D tech like this is super important for studying old stuff, and Pantheon 3D could be a game-changer for preserving our history. |
|
Hepworth, K. And Church, C. (2018). ‘Racism in the Machine: Visualization Ethics in Digital Humanities’. Digital Humanities Quarterly 12. An interesting paper that picks up on some of what we have been talking about in class previously. Talks about how human biases and prejudice can become reflected in digital humanities projects and considers the ethical dimensions of this. Uses digital maps of historic lynchings in the US as case studies. Shows how visual presentation of maps are inextricably linked to political views, I.e. whether state boundaries are shown or not implies a different view of lynchings as either a state specific or national problem. On maps that give an option to toggle state boundaries, the implication is that it is both. |
| Khunti, R., 2018. ‘The Problem with Printing Palmyra’. URL: https://scholarworks.iu.edu/journals/index.php/sdh/article/view/24590/32535.
The document analyses the ethical issues surrounding the reconstruction of Palmyra’s Arch of Triumph, which was destroyed by ISIS in 2015. The Institute for Digital Archaeology (IDA) used 3D printing to create replicas of the arch in New York, London, and Dubai. The author argues that the reconstruction failed to meet basic ethical standards in key ways, and that basic ethical principles that apply to preservation and display of original heritage sites should also govern digital reconstructions. |
|
https://wikimedia.org.uk/2018/03/data-on-the-history-of-scottish-witch-trials-added-to-wikidata/ A blog post sort of thing from Wikimedia Uk’s website, looking at a project from 2017 which uploaded the university of Edinburgh’s data on witch trials which had been sat in the cold cauldron of the university’s Microsoft Access database for a decade. Some 45 Design informatic Masters students uploaded the data to wikidata and produced various visualisations of the data. |
|
Zhao, Fudie. ‘A Systematic Review of Wikidata in Digital Humanities Projects’. Digital Scholarship in the Humanities 38, no. 2 (2023): 852–74. https://doi.org/10.1093/llc/fqac083. The aim of the systematic review was to identify and evaluate how Wikidata is perceived and utilized in Digital Humanities (DH) projects, as well as its potential and challenges as demonstrated through use. The paper found that:
|
|
Ford, H., & Iliadis, A. (2023). Wikidata as Semantic Infrastructure: Knowledge Representation, Data Labor, and Truth in a More-Than-Technical Project. Social Media + Society, 9(3). This article highlights how online platforms (google, alexa, amazon etc.) increasingly use Wikidata as a ‘critical architecture’ that links data throughout the world. The authors believe that Wikidata is a critical mediator of truth and thus has significant social and political implications. On a critical note they claim that due to the dissemination in discreet bits of information, these facts are not always anchored to their original references. They propose classifying Wikidata as a semantic infrastructure so that questions about its impact are more easily formulated. One of the challenges they note is Wikidata’s development as a public goods versus its use by downstream platforms that utilise its facts without credit. They end by highlighting two areas for future research; the study of knowledge automation/dissemination in an environment with few dominate commercial players and secondly, whether Wikidata is an alternative to ‘exploitive platform capitalism’ in the production of public knowledge goods. |
|
Sengul-Jones, M., 2021. ‘The promise of Wikidata.’ DataJournalism.com. URL: https://datajournalism.com/read/longreads/the-promise-of-wikidata |
|
Isaksen, L., Simon, R., Barker, E., and P. de Soto Canamares. ‘Pelagios and the Emerging Graph of Ancient World Data’. In: WebSci ’14: Proceedings of the 2014 ACM conference on Web science, ACM, pp. 197–201. https://oro.open.ac.uk/43658/1/2014_Isaksen_Barker_etal_Pelagios_WebSci.pdf Paper talks about the growth of the Linked Open Data Project GAWD (Graph of Ancient World Data. It explains for example that it uses simple ontologies such as Open annotation that makes it easier to adopt for people working in humanities who usually may not have a back ground in digital approaches. Also argues that there is still a lot of work to be done and offers several steps to be taken to integrate it. |
|
Claire S., “3D Printing & Intellectual Property: Are the Laws fit for Purpose”; In 3DNatives, July 3rd 2023 This website news article discusses the laws pertaining to 3D Printing and IP. It highlights the legal definitions pertinent to the field, the parties from 3D printing hobbyists to multinationals who seek to guard their discoveries with patents and trademarks. Different stakeholders are affected differently by the laws and may face different repercussions. Initially definitions for copyright, patents, trade secrets, trademarks, copyright law and 3D printing are outlined. The article also highlights the use of NDAs demanded of employees in 3D printing companies. There are movements that are fighting for change to the IP laws, such as Creative Commons that are trying to reform copyright laws so that the public has easier access to culture and knowledge. The article ends by saying that legal rulings tend to favour larger companies and may disfavour open creativity. It lists some individuals and organisations that are fighting for more open access to creative works and a modification of copyright laws. But, overall the IP laws that are applicable to 3D are complex and look set to become more nuanced and important in the immediate future. The website has been in existence since 2013 and was acquired by the American Society of Plastics Engineers (SPE) in 2023. Its mission is to bring the “wonders of 3D printing to as many people as possible. |
|
https://www.gla.ac.uk/news/headline_1012014_en.html A short news article which demonstrates the application of XR in museums/cultural heritage. The university of Glasgow through its project “The Museums in the Metaverse project” aims to create a virtual platform where any user with a vr headset can interact online with a Museums entire collection – which not only gives the public a new experience, but opens the door for academic study, as apparently about 90% of a museums collections are held in storage. |
|
Kantaros, A., Soulis, E. and E. Alysandratou, (2023) ‘Digitization of Ancient Artefacts and Fabrication of Sustainable 3D-Printed Replicas for Intended Use by Visitors with Disabilities: The Case of Piraeus Archaeological Museum’. Sustainability 15: 1-18. https://www.mdpi.com/2071-1050/15/17/12689 Article that touches on one of the topics that came up in the Thursday seminar. Specifically, it gives one answer to what 3D modelling and printing can be useful for. It uses 2 statues recovered from Piraeus as case studies for how these technologies can enhance learning for people who are blind or visually impaired. Article argues that 3D printed copies will allow people to interact with these artefacts through physical touch and therefore give them a clearer sense of the objects. The authors also argue that 3d printing and modelling have a lot of potential ‘to be purposefully crafted and modified in order to cater to a diverse range of disabilities, including but not limited to visual impairments, hearing impairments, and mobility limitation’. |
|
Loder, William. ‘Designing Digital Antiquity: Classical Archaeology in New Virtual Applications’. M.A. dissertation, University of Arkansas, 2021. https://scholarworks.uark.edu/etd/4251. In this thesis, William Loder explores the integration of archaeological theory with game design principles to create immersive 3D applications of ancient sites in virtual reality. By combining concepts from phenomenology and sensory studies with game design theory, Loder aims to enhance interactive education and research opportunities in classical archaeology. The focus is on developing a Virtual Roman Retail Project (VRR) application that allows users to explore a reconstructed shop scene in Pompeii, engaging with historical contexts and material data through interactive experiences. The methodology involves a blend of photogrammetry and 3D modeling techniques to accurately recreate the ancient environment. Loder emphasizes the importance of embodiment and presence in virtual landscapes for a more immersive learning experience. The thesis also discusses the challenges of digital reconstruction in archaeology, highlighting the need for constant interpretation and iteration to ensure accuracy and relevance in research. |
|
Muenster, Sander. ‘Digital 3D Technologies for Humanities Research and Education: An Overview’. Applied Sciences 12, no. 5 (25 February 2022): 2426. https://doi.org/10.3390/app12052426. The article explores the use of digital 3D technologies in humanities research and education. It covers key concepts, such as methodological settings, scientific communities, workflows, technologies for creating and visualizing 3D models, documentation standards, and framework conditions. The study investigates the impact of 3D technologies on cultural heritage studies and discusses funding sources, ethical considerations, and acknowledgements. Additionally, it highlights the importance of collaborations and networking in advancing research in this field. |
|
Barratt, R. P. (2021). Speculating the Past: 3D Reconstruction in Archaeology. In E. M. Champion (Ed.), Virtual Heritage: A Guide (pp. 13–24). Ubiquity Press. http://www.jstor.org/stable/j.ctv2dt5m8g.6 The chapter comprehensively discusses the main uses, methods, and issues of 3D reconstructions in archaeology. It offers a balanced perspective on the advantages (e.g. new opportunities for archaeological interpretation) and limitations (e.g. indistinguishable hyperrealism) of 3D reconstructions, while also presenting practical solutions to address the issue of inaccuracy in 3D models. The author’s discussion of games and their ability to create immersive learning experiences is especially relevant for those seeking to engage the public with archaeological heritage. |
|
Götz, S. (2024), virtual 3D Reconstruction of Ancient Architecture in the Ostia Forum Project in Ostia Forum Projekt Website This article describes how the Ostia Forum Project which is run by the Stiftung Humboldt-Universität has been working with the structure-from-motion (SfM) method. In 2020 the project began with creating virtual 3D reconstructions of various construction phases, fragments, altars, temples and the plaza of ancient Ostia. The aim was to include the possibilities of examining lines of sight, walkways and incidence of light. It has merged the 3d reconstructions based on polygons with models from 3D photogrammetry. This article provides the current reconstruction of the the Temple of Roma and Augustus in the Forum. The result is a walk-in 3D model that can be explored and compared with other buildings. Additionally, light effects during the day and throughout the year have also been included. |
|
P. Lassandro, M. Lepore, A. Paribeni, M. Zonno, 3D MODELLING AND MEDIEVAL LIGHTING RECONSTRUCTION This article examines the use of photogrammetry and laser scanning as techniques to create 3D models of byzantine churches in Italy to examine the systems of illumination of the buildings in the medieval times. |
|
G. Kontogianni, A. Georgopoulos, N. Saraga, E. Alexandraki, K. Tsogka, ‘3D VIRTUAL RECONSTRUCTION OF THE MIDDLE STOA IN THE ATHENS ANCIENT AGORA’. The International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences. Article talks about the process of reconstructing the Middle Stoa from the Athenian Agora as a 3D model. Data for reconstruction was ranked according to accuracy before implemented. For example, previous 3D models and other modern reconstructions were considered highly accurate while travellers’ reports were seen as less so. At times, the authors may have leaned on the supposed accuracy of modern models a little too much. When describing how they applied colours to their version of the building, they claimed that they only used one modern reconstruction as evidence. However, they don’t elaborate on what evidence was used by this previous study or what the previous authors’ assumptions were. It therefore felt that we just had to take their word for it. |
|
Horne, R. (2020). Mapping Power: Using HGIS and Linked Open Data to Study Ancient Greek Garrison Communities. In: Travis, C., Ludlow, F., Gyuris, F. (eds) Historical Geography, GIScience and Textual Analysis. Historical Geography and Geosciences. Springer, Cham. https://doi.org/10.1007/978-3-030-37569-0_13 The chapter talks about how developments in LOD have helped make new advancements in the study of ancient Greek garrisons. The author makes a gazetteer that shows every Greek garrison throughout antiquity. The chapter argues that this would have been impossible before with LOD since many humanities data sets are derived from textual sources which offer little geospatial data, therefore complicating the use of GIS. However, after aligning data with information on Pleiades, a complete overview of Greek garrisons was possible. After making this gazetteer, it was found that garrison commanders were usually only ever found in areas peripheral to ruling powers and never in imperial capitals. |
|
Rantala, H., Ikkala, E., Koho, M., Tuominen, J., Rohiola, V., & Hyvonen, E. (2021). Using FindSampo Linked Open Data Service and Portal for Spatio-temporal Data Analysis of Archaeological Finds in Digital Humanities. CEUR Workshop Proceedings, 2980. http://ceur-ws.org/Vol-2980/paper330.pdf This paper talks about FindSampo(a LOD service and semantic portal) that is based on Finnish Citizen Science archaeological data and has been in use since May 2021. It is a collaboration between the public, archaeologists and heritage managers in Finland. Currently there are more than 3,000 archaeological finds made by the public in the data service, which can be searched and results can be visualised in maps, charts and a timeline. Most finds are derived from metal detecting and therefore their visualisations also provide information on further places that are recommended for detecting and those that should be avoided. Querying data is carried out with SPARQL. In future, the framework will be adapted for international archaeological finds as well. |
|
Blaney, Jonathan. ‘Introduction to the Principles of Linked Open Data’. Programming Historian 6 (2017). https://doi.org/10.46430/phen0068. This is a lesson from Programming Historian, which is a good introduction to the main aspects of Linked Open Data like URI, RDF, SPARQL, etc. It explains the several advantages of this technology of Semantic Web, but also some of the pitfalls and difficulties. The lesson then uses Linked Open Data through examples to demonstrates how academics can publish or use this techonology for their own research. |



 Call for Presentations
Call for Presentations
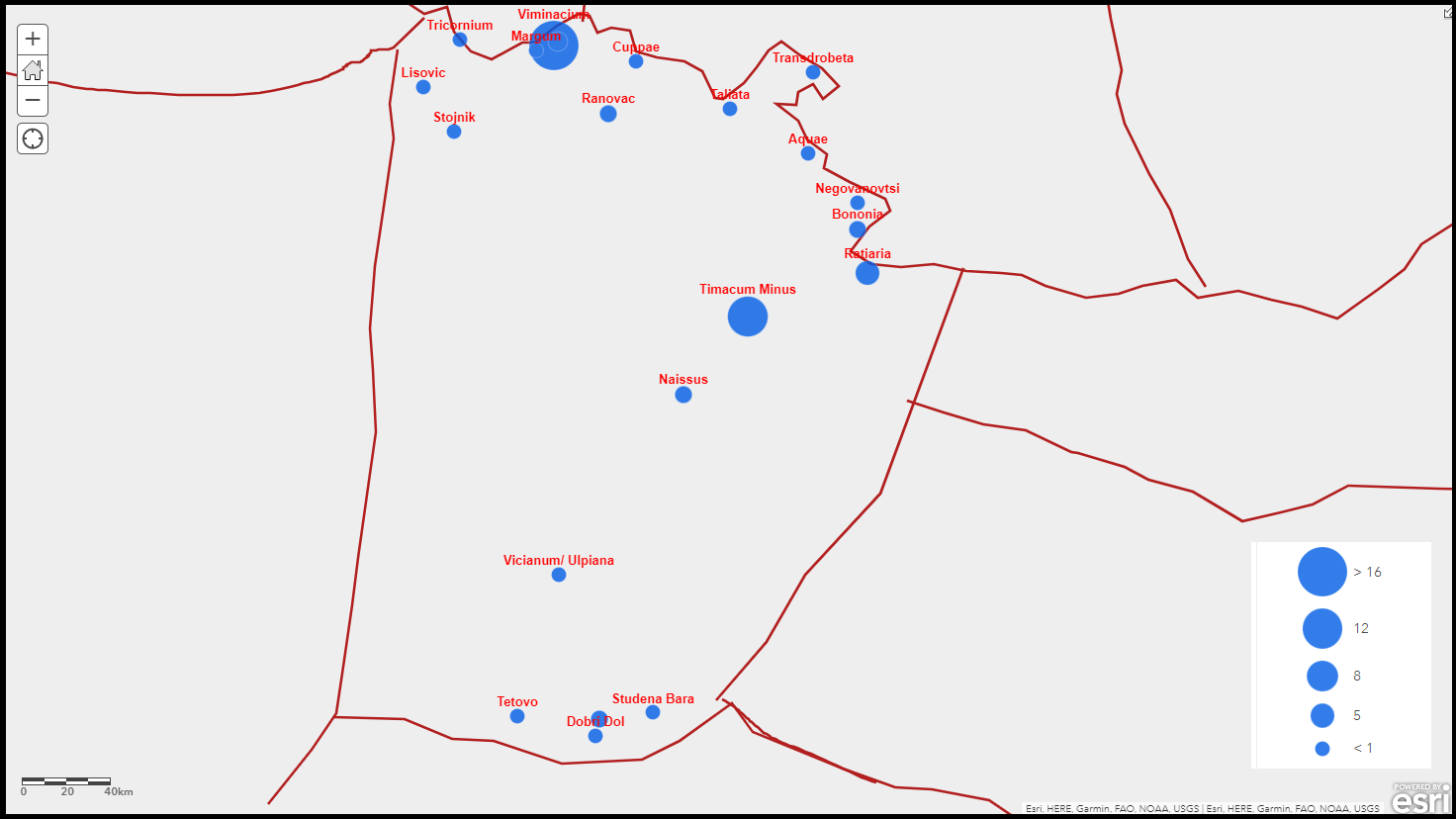
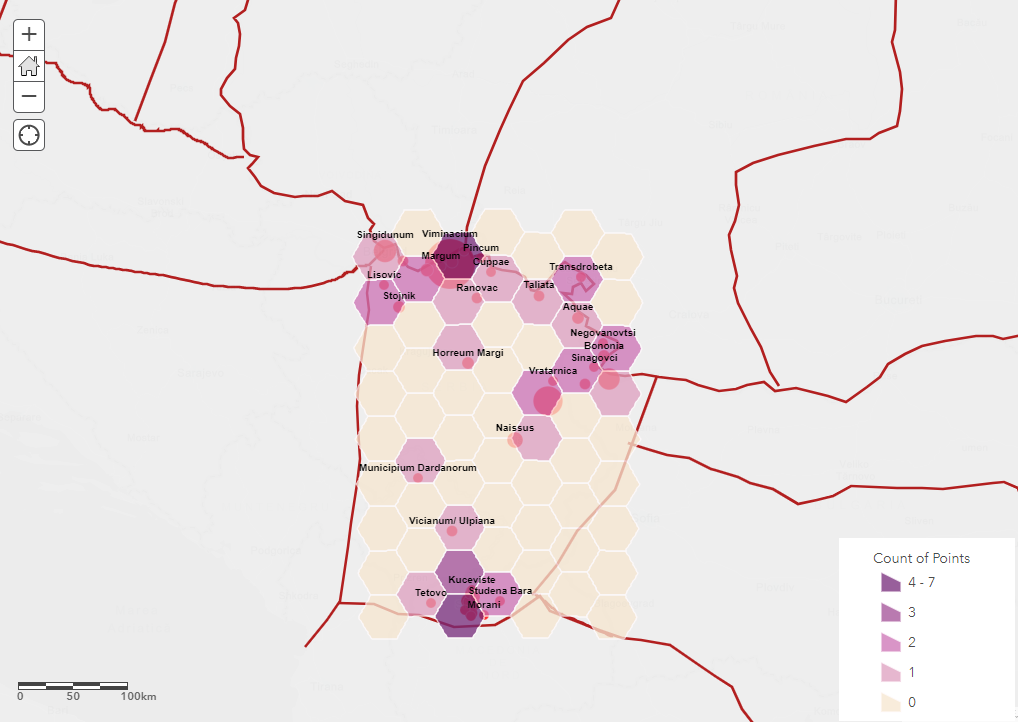
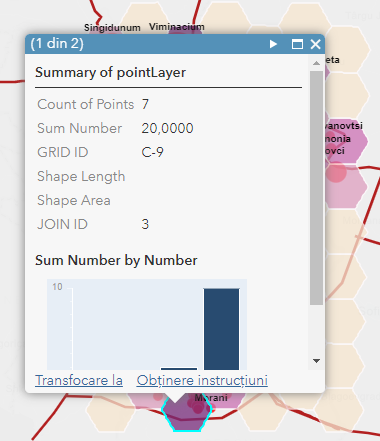
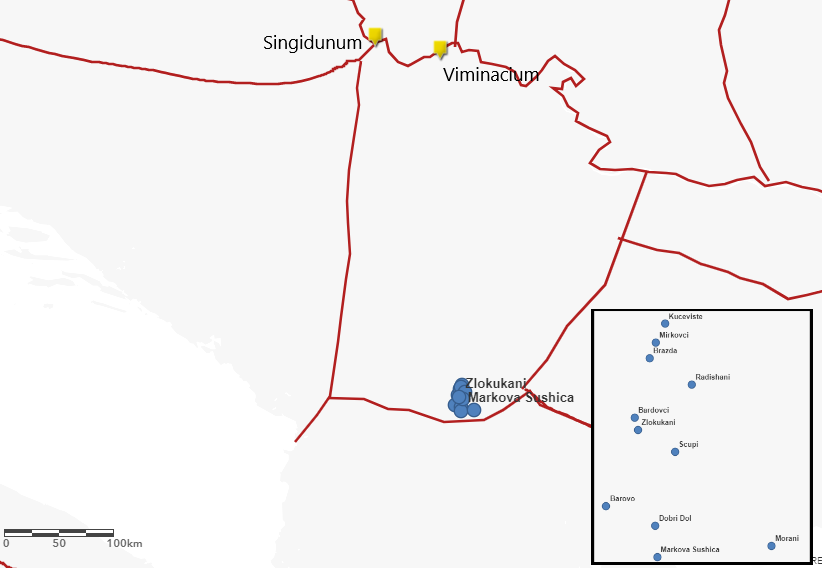
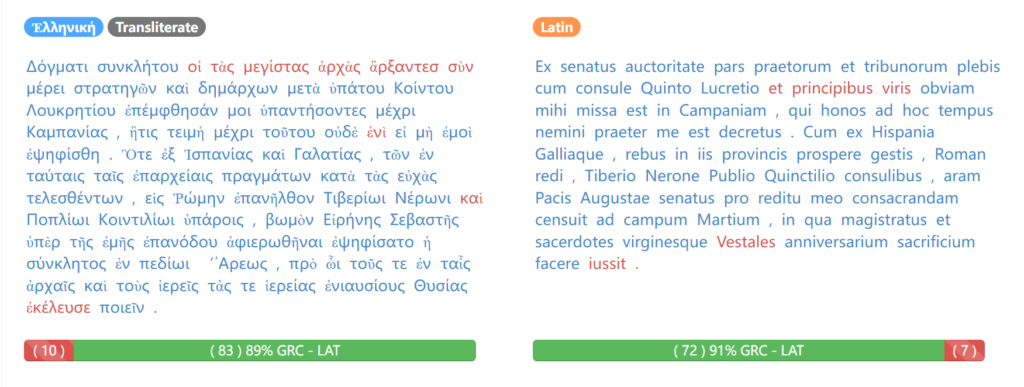
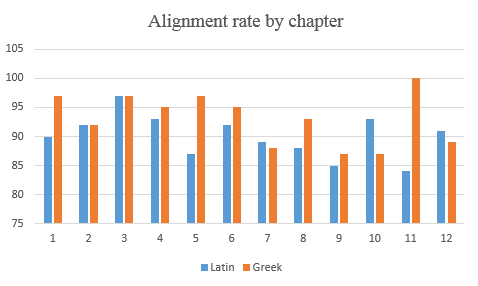
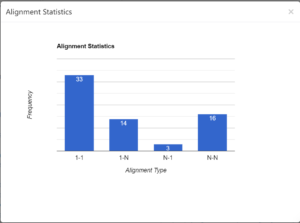

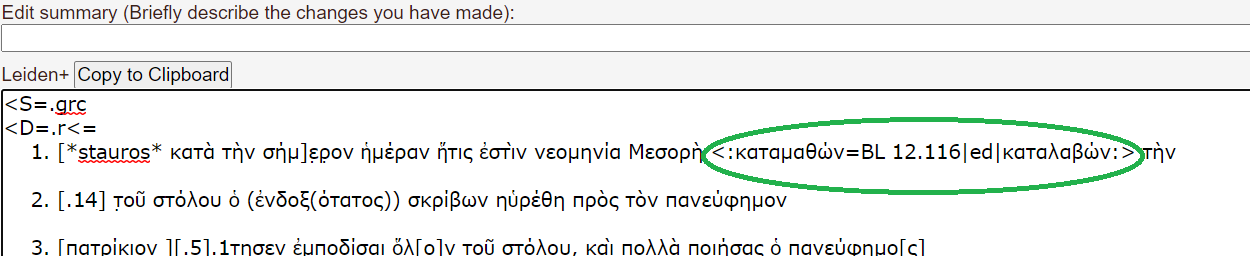
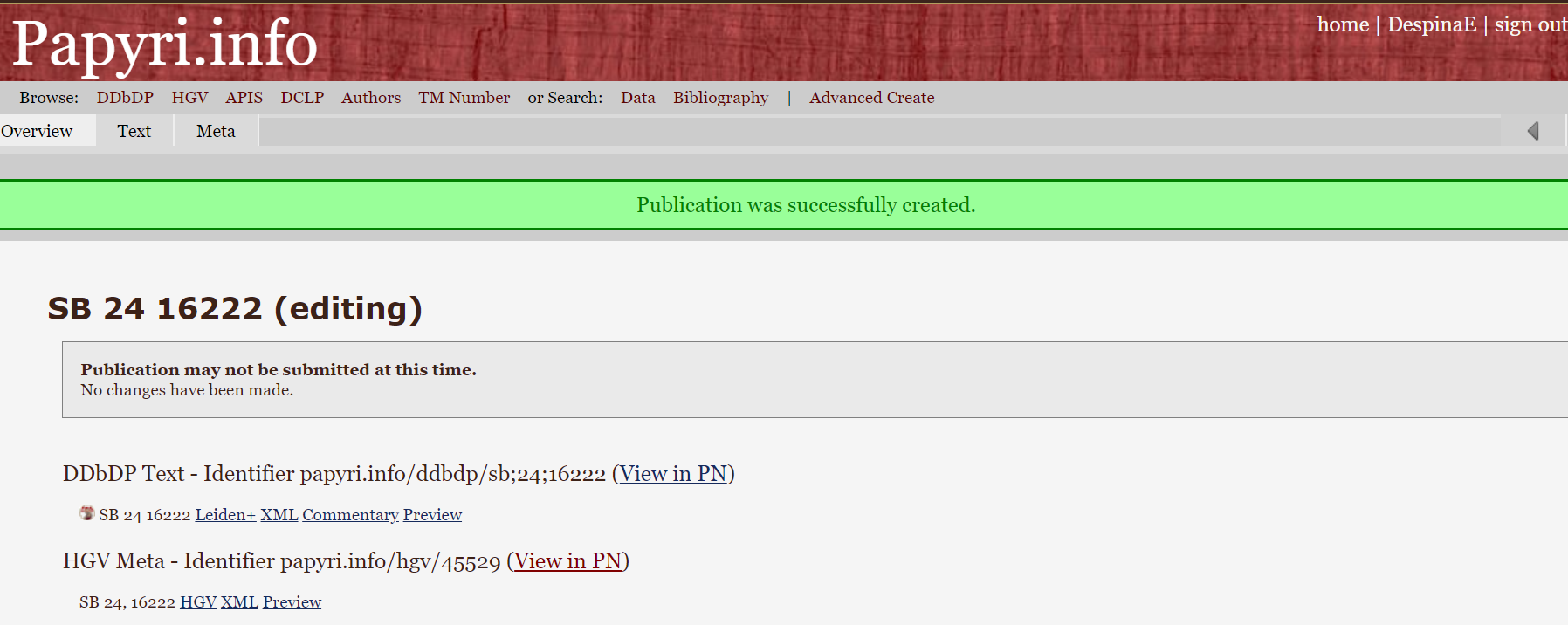



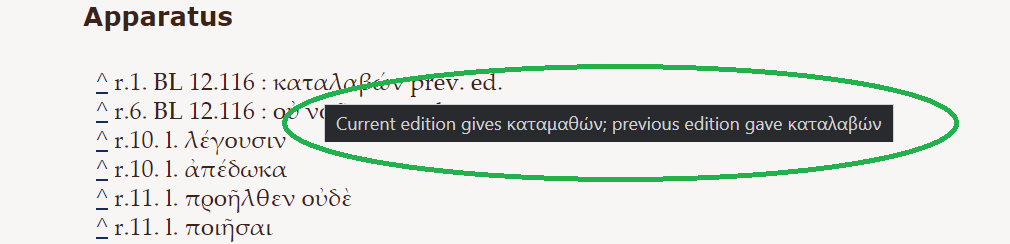



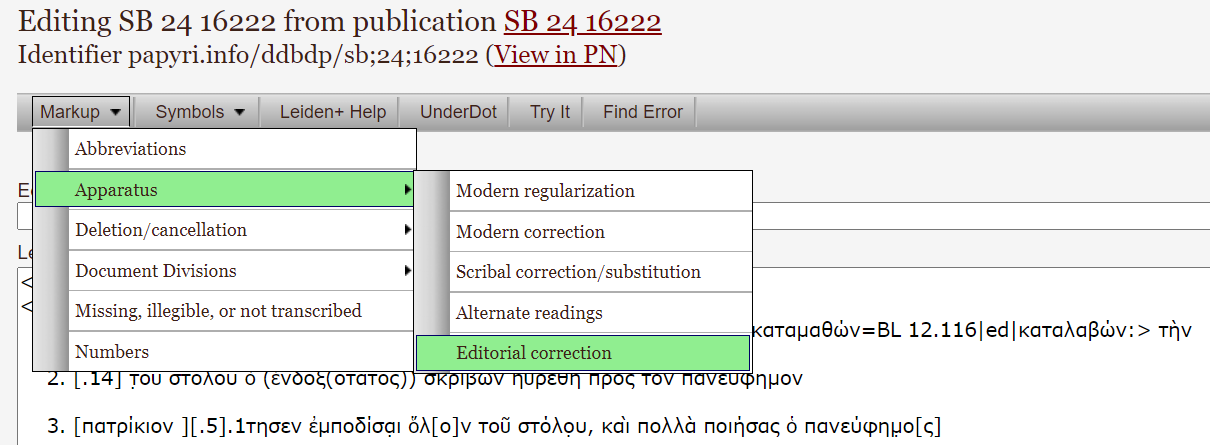
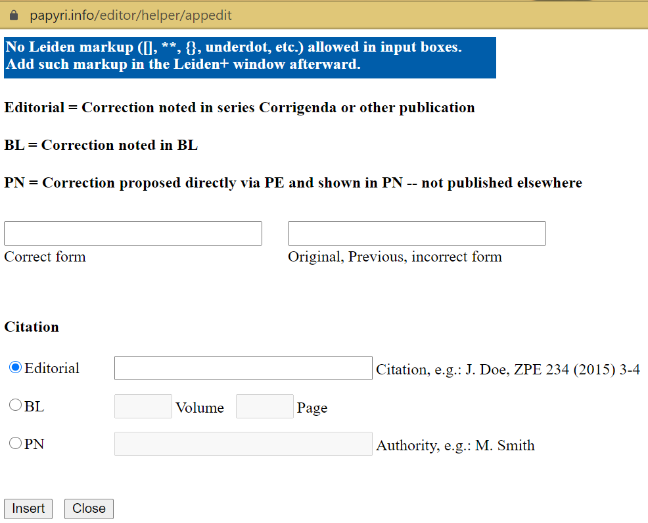
 The Papyrological Editor also includes a
The Papyrological Editor also includes a 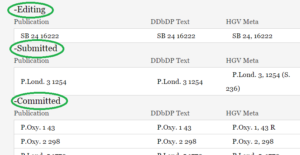 Lastly, one key strength of the PE lies in the appearance of Leiden+. With the exception that ‘Leiden+ must in some cases be more verbose than traditional Leiden, (…) due to the fact that Leiden+ must be able to be transformed into unambiguous, valid EpiDoc XML’ (
Lastly, one key strength of the PE lies in the appearance of Leiden+. With the exception that ‘Leiden+ must in some cases be more verbose than traditional Leiden, (…) due to the fact that Leiden+ must be able to be transformed into unambiguous, valid EpiDoc XML’ (

 Before I arrived at the ICS, Gabriel provided me with some video tutorials and suggested that I familiarise myself with the theory and practice of photogrammetry, the process of combining multiple 2D images to create a 3D model using specialised software. The tutorials provided me with sufficient knowledge to photograph the objects myself, and to merge them using Agisoft Metashape and Autodesk MeshMixer. Over the two-week period, I was able to successfully digitise six items from the library’s collection, putting aside a couple more after several failed attempts at producing a complete model. These latter items were similarly imaged from inside a light tent (shown above right), but their uniformly black surfaces proved too reflective for the software to accurately identify and so the model was repeatedly rendered with gaps. Through trial and error, I learnt that more detail often correlated with greater accuracy in the final 3D model as the software was able to detect a higher number of overlapping points.
Before I arrived at the ICS, Gabriel provided me with some video tutorials and suggested that I familiarise myself with the theory and practice of photogrammetry, the process of combining multiple 2D images to create a 3D model using specialised software. The tutorials provided me with sufficient knowledge to photograph the objects myself, and to merge them using Agisoft Metashape and Autodesk MeshMixer. Over the two-week period, I was able to successfully digitise six items from the library’s collection, putting aside a couple more after several failed attempts at producing a complete model. These latter items were similarly imaged from inside a light tent (shown above right), but their uniformly black surfaces proved too reflective for the software to accurately identify and so the model was repeatedly rendered with gaps. Through trial and error, I learnt that more detail often correlated with greater accuracy in the final 3D model as the software was able to detect a higher number of overlapping points.







