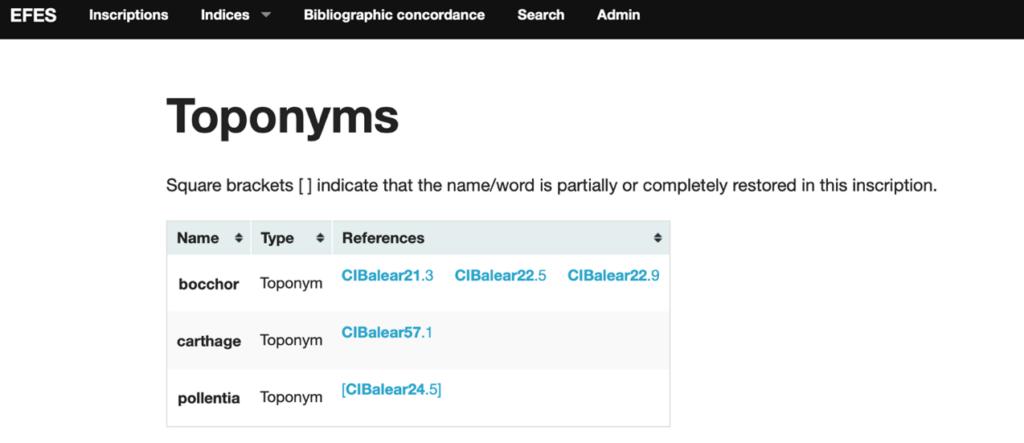
Digitizing Antiquities: A 3D Photogrammetry Placement at the Institute of Classical Studies
by Kiwa Chen and Kei Dai
During a two-week placement in the Senate House MakerSpace, University of London, in April and May 2026, my partner Kei and I focused on the 3D digitization and documentation of antiquities held by the Hellenic and Roman Library at the Institute of Classical Studies (ICS). Fulfilling a core component of our MA in Digital Humanities at UCL, this project allowed us to step out of the classroom and directly apply computational methods to the tangible preservation of archaeological heritage.
The ICS Library holds a fascinating collection of over 150 small antiquities, primarily Greek and Roman ceramics. These artefacts were bequeathed to the Institute by Dr. Victor Ehrenberg in 1976 with a clear and generous intention: they were not to be locked away, but rather used actively for handling and teaching. Today, this ongoing digitization initiative honors Ehrenberg’s vision. By producing high-quality 3D models of the collection using photogrammetry, we are able to upload these artefacts to the ICS Sketchfab account. This project not only meets the original mandate of teaching and handling but dramatically increases global access to, and engagement with, the Library’s collection.
Settling into the MakerSpace Workflow
Under the attentive and expert supervision of Dr Gabriel Bodard (Gabby), we were introduced to the foundational workflows of 3D modelling. Our digitization took place at the Senate House MakerSpace, a collaborative environment managed by the Digital Humanities Research Hub. We were equipped with a Nikon D850 digital SLR camera to capture high-resolution images, which we subsequently processed using Agisoft Metashape Pro.
Over the course of the two weeks, our principal tasks were threefold: photography and photogrammetric processing, meticulous documentation of our workflows, and archiving the resulting images and models. In total, we successfully modelled three distinct artefacts: two fragile ceramic sherds and one stone statuette.
Week One: The Ceramic Sherds and the Sponge Solution

Figure 1. Ehrenberg 18. Mycenaean Sherd
During our first week, Gabby thoughtfully suggested that we start with slightly simpler items to familiarize ourselves with the equipment, lighting, and software. Kei and I selected two ceramic fragments: the “18. Mycenaean sherd” (Figure 1) and the “16 Black-figure Sherd” (Figure 2).
This artefact is a light tan pottery sherd, possibly dating to the second Late Minoan period (L.M.II?, 1470-1420 BC), originally found at Tiryns in 1925. Measuring 68mm in height, 51mm in width, and 6mm in depth, the obverse is decorated with faded brown and red horizontal stripes. The reverse bears the fascinating handwritten inscription “Tirynes.”

Figure 2. Ehrenberg 16. Bf. Sherd
This black-figure sherd was acquired in 1925 as a gift from a shopkeeper in Athens. The obverse depicts an animal, likely a boar, with some paint loss across the body, while the reverse is glazed entirely in black. Interestingly, the item comprises two fragments visibly adhered together. Judging by its color, the adhesive appears to be animal glue, though the date of this historical repair remains uncertain.
See the 3D models in Sketchfab:
Challenges and Problem Solving
Our immediate challenge with these fragments was their physical shape. Unlike flat-bottomed objects, these sherds could not stand upright on the turntable. To capture a full 360º view, we needed a way to support them without obstructing the camera or damaging the 3,000-year-old terracotta.
Gabby helped us devise an ingenious, non-destructive solution: we carved a small groove into a piece of soft sponge. By gently resting the fragment within this groove, we could securely hold the item in place. We photographed the sherd in one orientation, then flipped it upside down in the sponge to photograph the reverse side. This allowed us to generate two separate “chunks” (one for the top, one for the bottom) in Agisoft Metashape. Figure 3 shows this setup in action.

Figure 3. A ceramic sherd resting in the sponge support on the turntable during image capture
However, as we quickly discovered, relying on the software’s automatic chunk-merging feature rarely yields perfect alignment. To resolve this, we had to manually align the chunks point-by-point by adding corresponding markers across both halves. Yet, even with meticulous manual alignment, the two chunks rarely overlapped flawlessly, often leaving extraneous overlapping geometry where the halves met.
To refine the final piece, we had to use the selection tool to manually delete these redundant parts. This cleanup process required extreme spatial precision. We learned that finding the exact right angle to view and select the geometry was crucial; we had to constantly rotate the merged model in the 3D space to identify a “safe” perspective where we wouldn’t accidentally highlight the actual object. During our early attempts, failing to find this specific angle meant we occasionally deleted too much, resulting in missing gaps in the model itself. This iterative trial-and-error taught us that careful digital cleanup is just as critical as the initial photography.
Furthermore, the merging process faced additional hurdles with the 16 Bf. Sherd. The black glaze on the 16 Bf. Sherd proved highly reflective. In photogrammetry, inconsistent reflections across different photographs confuse the software’s alignment algorithms, as the “highlights” appear to move across the object’s surface. Consequently, our first attempts at merging the chunks resulted in slight blurriness and less-than-perfect geometry.
Week Two: Tackling the Stone Statuette

Figure 4. Ehrenberg 30. Sitting Baboon
Armed with the hard-earned lessons regarding lighting and reflection from week one, we challenged ourselves in week two with a significantly more complex object: the Sitting Baboon (Figure 4).
This Hellenistic or Roman Egyptian stone statuette depicts a baboon in a traditional squatting pose, measuring 112mm high. Its recorded provenance includes a December 1957 Sotheby’s auction where it was acquired by Ehrenberg, marking it as a significant collector’s piece. However, its history prior to this auction remains entirely unknown. There are no surviving records to indicate where it was discovered or housed before entering the art market.
Because of its intricate physical geometry, the statuette required a highly sophisticated capture strategy. To combat the reflection issues we encountered with the black sherd, we deployed black umbrellas around our lighting setup. This absorbed excess, bouncing light and diffused the light source, dramatically reducing specular highlights on the stone’s surface.
Furthermore, the squatting posture of the baboon created deep shadows and hidden geometries, particularly beneath the chin, around the neck, and at the very base of the statuette. To capture these occluded areas, we adjusted our tripod to shoot from low, upward-facing angles. Just as with the sherds, we photographed the baboon in multiple passes, flipping the object carefully to capture its underside, and successfully merged the resulting chunks into a highly detailed and cohesive 3D model. The finished model can be viewed, rotated, and explored interactively on Sketchfab.
Reflections
This two-week placement was a profoundly enriching experience. While both Kei and I entered the MakerSpace with some prior digitization experience, working directly with the Ehrenberg Bequest pushed us to explore new possibilities and refine our technical troubleshooting skills.
We are immensely grateful to the Institute of Classical Studies and the Digital Humanities Research Hub for providing us with this opportunity. The environment afforded us a remarkable degree of creative freedom, time, and space to experiment, fail, learn, and ultimately succeed. We gained invaluable practical insight into the complexities of cultural heritage imaging, and we take great pride in knowing our 3D models will help preserve these antiquities for future generations of students and scholars to study, no matter where they are in the world.
To cite this article:
Chen, Kiwa and Kei Dai. 2026. “Digitizing Antiquities: A 3D Photogrammetry Placement at the Institute of Classical Studies.” Stoa Review. Available: https://blog.stoa.org/archives/4420. DOI: https://doi.org/10.83330/stoareview.4420.