
Textual Alignment of Res Gestae: Translation in Historical Languages
by Sisi Xie
Commenting on the Ugarit alignment tool: https://ugarit.ialigner.com/
1. Introduction
Res Gestae Divi Augusti (RG), written by Augustus during his lifetime, is a direct reflection of the posthumous image that he intended to leave engraved. It was initially inscribed in Latin on two bronze steles in front of the mausoleum of Augustus at Rome. The Greek texts were translations targeted at the Greek audience who might not have direct access to the Latin original. The textual comparison of RG in two historical languages has attracted considerable scholarly attention, before the advent of digital tools. As previous research has shown, text alignment by hand and paper generates reliable and insightful conclusions (e.g. Cooley’s Res Gestae Divi Augusti, 2009, 26–30). The development of digital humanities opens up more possibilities to perform research via diverse approaches, among which Ugarit is a well-developed online tool designed for textual alignment.
Textual alignment, or translation alignment in the case of RG, is one type of annotation to link a word or expression in a text with the matching one in the correspondent text, creating aligned word pairs. Parallel texts can be written in different languages or come from different versions of the same source. Ugarit’s user-friendly interface presents visualized data of textual alignment, including easily recognized translation pairs, alignment statistics, rates of correspondence and others. While enjoying wide popularity in alignment of ancient texts and modern translations, it also shows a research potential in matching texts from multiple historical languages, especially those in which the original version and the translation have been distinguished. RG, like the Rosetta Stone, is a suitable bilingual sample for Ugarit to reveal the correspondence and divergence in source texts and translated texts. It is the aim of this project to examine whether Ugarit could provide a better insight into the comparison of bilingual texts of RG than paperwork, and what more benefits Ugarit could provide than non-digital methods. More specifically the project tries to investigate via Ugarit what strategy the Greek translators adopted and how much the translation followed or deviated from the original Latin.
2. Alignment
With the Latin as source texts and the Greek as target texts, the project connects each word in the translations with source texts. The alignment focuses more on the semantical relation rather than syntactical. Pairs are aligned when an attempt to translate words in the source texts is detected and a Greek equivalence is created, regardless of accuracy. This could result in a higher alignment rate, though some pairs aligned are not necessarily precise correspondents. Further evaluations on whether the translation truly reflects the desired meaning of the source texts and to what aspect the distortion goes are recorded beyond the web tool, using pen or computer. Only the first twelve chapters are aligned given the length of RG. The conclusion of alignment is built on the one hand from the visualisation and statistics automatically generated by Ugarit, and on the other from notes taken manually outside Ugarit.
Ugarit offers general and instantly visible results on the dashboard after the manual alignment process is finished, but information emerges during the process of alignment, much of which cannot be detected from the final visualization. A word-to-word alignment practice continuously reveals the degree of loyalty of Greet target texts to the source texts. Based on the twelve chapters examined, the purpose of translation was to create a Greek reduplication of Latin source texts as precise and comprehensive as possible. A combination of various strategies was used to minimize the chance of negligence and distortion: literal translation, transliteration and liberal translation.
Literal translation, which was the most frequently adopted technique, matched each Latin word with a Greek correspondent and closely followed the word order of Latin source texts. The preciseness of literal translation finds its best evidence on Latin particles, which in most cases were allocated Greek equivalence, though their absence had little influence on the core meaning of the sentences. At times the translators adjusted the word order to make it more idiomatic for the Greek audience. The translation pattern adopted a more flexible structure and appeared like a reorganization of the original puzzle, of which few pieces were left and the overall picture remained largely the same. When applicable, Latin source words were replaced by Greek words of the same part of speech, but exceptions existed. Perpetum as an adverb in chapter 5 was translated into a prepositional phrase διὰ βίου, and similarly prospere in chapter 12 was replaced by κατὰ τὰς εὐχὰς.
Transliteration was adopted mostly on proper names of Latin that sounded unfamiliar to the Greek audience, such as names of Roman gods, magistrates, or verbs that harboured unique meanings in the Roman context. The translators judged it unnecessary to explain the exact meanings of the proper name, or there was simply no Greek correspondent that made any sense. Fetialis and saliare (salis) were rewrote in Greek alphabet as φητιᾶλις and σαλίων (RG. 7.3, 10.1).
Liberal translation, or loose translation that shows a weaker link with the source texts, occurred in the following conditions: 1) auxiliary expressions were needed to compose a fluent sentence. In chapter 9, besides translating conjunctive adverbs aliquotiens…aliquotiens into τοτὲ…τοτὲ, an additional pair of μὲν…δὲ was added to better suit the Greek idiomatic writing habit. 2) The meaning of the Latin source words required further explanation, or existing Greek vocabularies failed to give meaning to the Latin source words. Triumvirum in chapter 1 was expanded into τὴν τῶν τριῶν ἀνδρῶν ἒχοντα ἀρχὴν, and later in chapter 7 abbreviated into τριῶν ἀνδρῶν. Again in chapter 7, princeps senatus found its explanation as πρῶτον ἀξιώματος τόπον ἒσχον τῆς συνκλήτου. Expansion and differentiated translations for the same word indicate that the translators were not mechanically spotting a resembling piece of a puzzle only by appearance, but their aim was to compose a readable translation when it still fell within their ability. Exempla was used twice in 8.4. The translators make the first into ἐθῶν and the latter μείμημα.
A more flexible word order and a greater degree of liberal translation reflect the difficulty in sorting out proper Greek expressions for Roman events and phenomenons. Sentences concerning political concepts, specified practice and religious affairs experience more omission and distortion. Details in narration are countered by disorder and omission when it comes to the actual power Augustus had gained, which he took caution to veil. The translators thought a single δουλήσας sufficient to describe Augustus’ effort in liberating the Romans, leaving oppressam that modified rem publicam as well as in libertatem untouched (RG. 1.1). In the religious sphere, the translators did not bother to make clear distinctions between groups of priests with variable names and duties. XVvirum sacris faciundis and VIIvirum epulonum were indiscriminately translated into ἀνδρῶν τῶν εροποιῶν. Pontifices and virgines Vestales were only distinguished by their sexual difference, one in masculine τοὺς ἱερεῖς and the other in feminine τὰς ἱερείας (RG. 7.2, 11). Even in literal translation, unintentional distortion or misinterpretation cannot be avoided given the different cultural backgrounds and natures of languages. Imperator in the Augustan discourse does not necessarily contain the absolute rule that αὐτοκράτωρ conveys, and πολεῖς is not perfect equivalence of municipatim (RG. 4 and 9).
Results
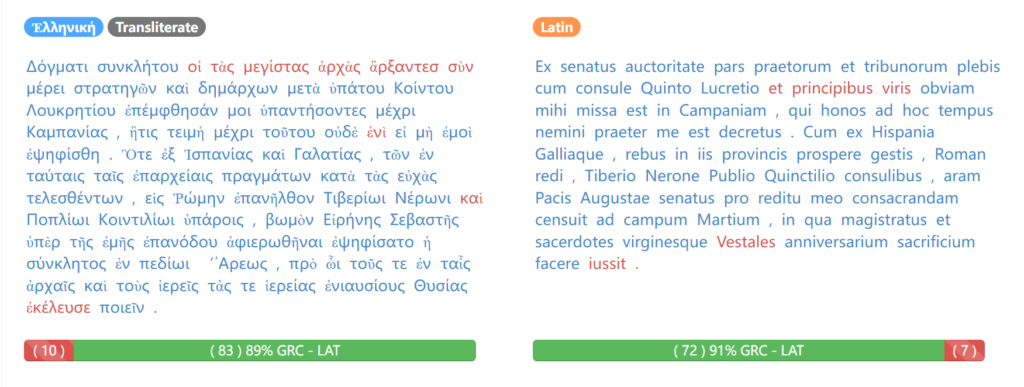
Figure 1 Preview Page
Statistics and visualisation generated by Ugarit shed light on the translation tactic from a broader perspective. Visually it is easy to identify the aligned pairs of expressions and the remaining unaligned parts by their differences in colours. At the bottom of the “preview” page, one can find two percentage bars showing the proportion of words aligned (screenshotabove). A summary of the alignment rates in each chapter (screenshot below), which is not given by Ugarit, provides an insight into how fully translated each chapter was. The gaps of chapter 5 and 11 may indicate a considerable number of untranslated Latin words, while that of chapter 10 an attempt by the translators to extend the interpretation of unfamiliar Latin concepts. But for other chapters, no safe conclusion can be drawn, given the nuance in number. A gap of 7% is not necessarily the sign for a looser translation than that of 2%, if taking into account that too many elements have a hand on the final result. One reason for the Latin rates falling below the Greek ones is that word amounts of Latin texts are usually smaller than the Greek, so one untranslated Latin word results in a greater drop of rate than a Greek word.
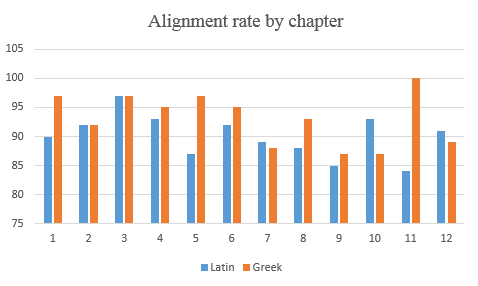
Figure 2 Alignment rate by chapter
Translation pairs are singled out in a separate chart, with the frequency of each pair included. The chart is potentially useful in detecting if a set phrase in Latin was consistently translated into another set expression in Greek, but to make the statistics more accurate, both texts input have to be lemmatised first. The alignment statistics presented in the bar chart calculate the number of 1-N, N-1 and N-N pairs. For example, it can be safely concluded from the chart of chapter 1 (screenshot below) that 1-1 alignment was the most frequently used translation techniques, which can also be observed during the alignment process. The high frequency of 1-1 alignment could attest to the loyalty of Greek translation to find a correspondence for each word in the Latin texts. Yet the major results, including the proportion bars, translation pairs and alignment statistics, are infected by the alignment strategy and the nature of languages involved. Setting criteria of eligible alignment is based on the users’ judgement of what counts as recognisable translation to their knowledge. Also, the 1-N alignment results not only from the different cultural backgrounds of Greeks and Romans, as Greek texts used more words to explain one Latin word; but also from the fact that each Greek noun had an article, and consequently a Greek noun group contained more words.
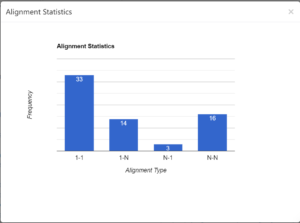
Figure 3 Alignment statistics of chapter 1
Conclusion
Both the process and results of alignment reveal an interesting combination of translation techniques used in the Greek translation of RG. The translators followed 1-1 literal translation whenever possible, but never aimed to produce an accurate scholarly translation that modern editions of ancient texts strive for. The desired outcome was an easy-to-read but close paraphrase of the original inscribed Latin, in which occasional omission and misinterpretation were tolerable. But this is only a premature observation of the phenomena shown in translation, not the reasons behind them.
The process of judging and deciding whether a translation should be aligned places its users into a similar situation with the Greek translators. They both have to consciously set a standard for eligible translation and to specify the main target of their practice. The repeated practice of moving and clicking the mouse reinforces a clearer awareness of textual correspondence, and the web-page storing alignment results enables frequent and convenient revisit. Statistics and visualisation reveal some aspects of alignment that might be overlooked by traditional alignment, inspiring users to probe deeper and provide explanations for the automatically generated results. Yet the more easily obtained alignment pattern and statistics are not the answer itself, but a reflection of one facet of the answer. The reasons behind such phenomena require more deliberation beyond the online tool. If the project is designed to unravel the reception of Greek provinces of the reign of Augustus and his disseminated propaganda, more understanding of the historical context of the excavated inscriptions and a sound mastery of the Greek language are indispensable. Overall, Ugarit effectively provides a platform to set the texts in alignment, enabling frequent and convenient revisiting and rechecking. It is only the starting point of textual alignment and comparison, but this starting point steps beyond the line that mere paperwork could draw.
